
Trends in the Compute Requirements of Deep Learning
How large and inefficient are deep models getting?

It’s pretty well known at this point that, at least at the top (see: all LLM research in the past 4 years), the compute footprint of deep models is increasing. This post will be pretty simple; I’ll review a handful of recent studies which have analyzed these trends across the field and across tasks, and provide some perspective and thoughts.
The Computational Limits of Deep Learning (Thompson et al. 2022) [1]
This paper does several broad analyses of compute trends in machine learning: the computational requirements of training different models across the field in terms of floating point operations per second (FLOPs) and the relationship between this and improvements in algorithmic and hardware efficiency, as well as performance on several benchmark datasets.
Taking a wide lens, they first illustrate that up until the switch to GPUs (as well as the slowing down of Moore’s law), improvements in hardware efficiency only slowly lagged behind the increasing computational demands of machine learning (and deep learning in particular). But with the recent explosion in model size, and the common response of simply adding as many devices and time as necessary to run such models, increases in compute vastly outpaces hardware improvements:

They highlight why this is a problem going forward:
Scaling deep learning computation by scaling up hardware hours or number of chips is problematic in the longer-term because it implies that costs scale at roughly the same rate as increases in computing power [35], which (as we show) will quickly make it unsustainable.
The authors then perform a large scale meta-analysis of >1,500 papers to relate computational burden and performance. They compare models which report results on several benchmark datasets (ImageNet, MS COCO, SQuAD 1.1, CONLL 2003, WMT 2014 EN-FR, and WMT 2014 EN-DE). One nice feature of this analysis is it allows them to observe trends in the amount of compute required to achieve a certain level of improvement in performance on each benchmark. Take imagenet for example:

(Note the log-log scale: a straight line indicates polynomial growth i.e. power law scaling)
…our estimated slope coefficient of −0.08 (p-value < 0.01) indicates that computation used for ImageNet scales as O(Performance^12.5). Concretely, this means that every halving of the remaining error on this problem requires ≈ 2^12.5 >5,000x as much computation.
These power-law trends hold across the tasks that they analyze:

Projecting these trends out into the future, to further reduce error rates on these datasets the computational and economic burden becomes untenable, so the authors offer three common sense suggestions for how to manage this:
Increase compute power by improving hardware accelerators or finding ways to switch to more efficient computing platforms e.g. neuromorphic computing or quantum computing.
Reduce computational requirements through e.g. compression
Discover more efficient networks through e.g. neural architecture search
Measuring the Algorithmic Efficiency of Neural Networks (Hernandez and Brown 2020) [2]
This paper takes a different perspective on efficiency, looking at algorithmic efficiency. The authors perform several experiments on state-of-the-art models in computer vision between 2012 and 2018 in order to quantify trends in the amount of compute required to achieve an equivalent level of performance on imagenet that AlexNet had achieved in 2012. Looking at efficiency in this light, they find that the algorithmic efficiency of CV models on imagenet improved by 44x over that time period, outpacing Moore’s law.

In other words, the amount of compute needed to solve imagenet to a fixed level of accuracy has decreased exponentially over time.
Compute and Energy Consumption Trends in Deep Learning Inference (Desislavov et al. 2021) [3]
This paper looks specifically at trends in the computation and energy required for inference over time. Inference is particularly important as the majority of computation and energy consumption for a given model, at least for a model which will be deployed in practice, is at inference [5,6].

For computer vision models, in terms of raw compute based on the number of FLOPs required for a single forward pass, the authors show that SOTA models are exponentially increasing over time. Considering all models which they studied, there is still an exponential trend upward, though at a much slower rate than for SOTA models. The same trend holds true for NLP models:
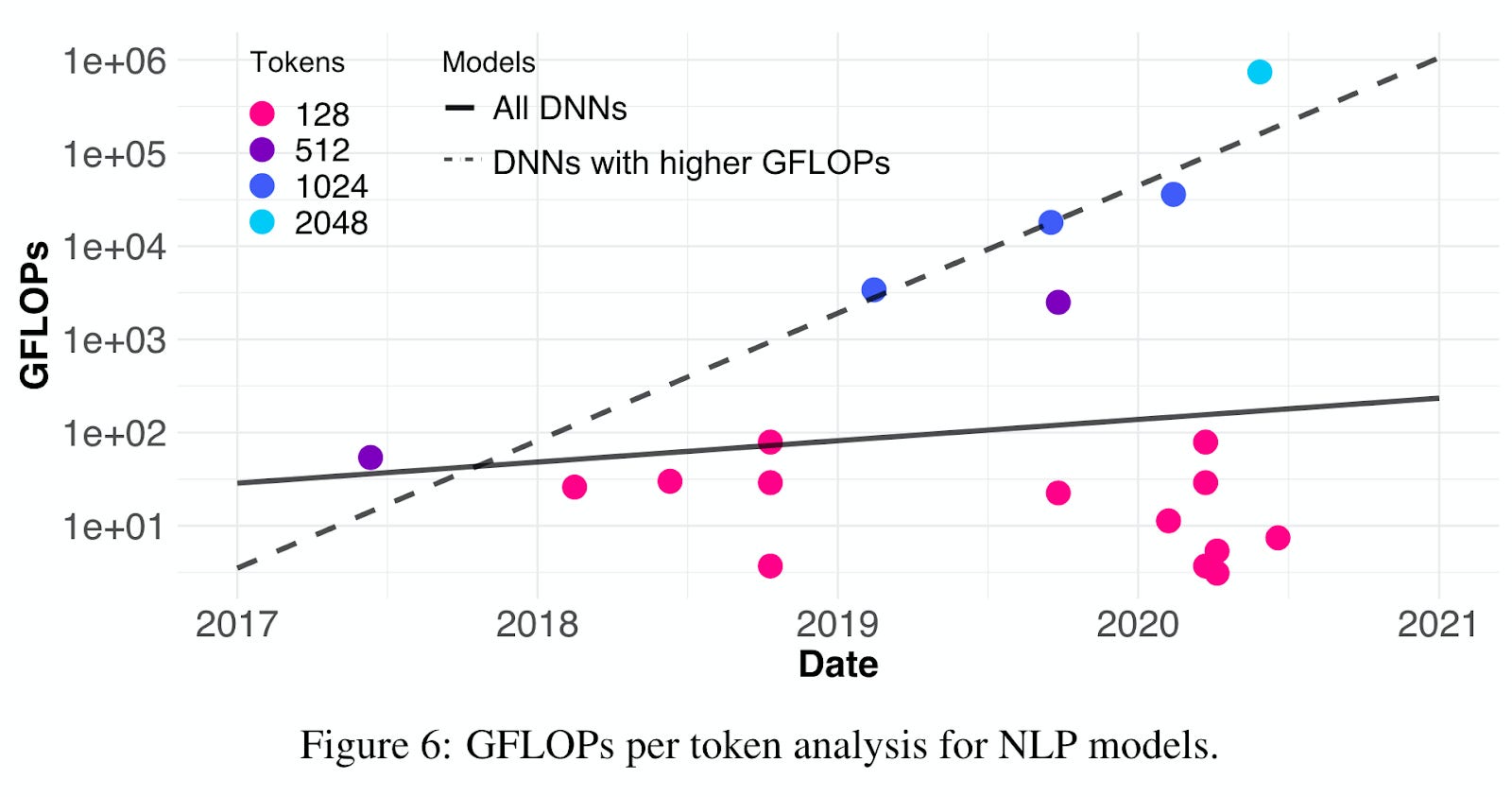
They then estimate the FLOPs/Watt for a range of GPUs over the same time period, and use this to estimate the total energy consumed for a single forward pass of the models surveyed in their study, plotting the trend in energy consumption for inference over time:

Similar to the results for computation, the trend for SOTA models is an exponential increase in energy consumption for inference over time, but due to improvements in hardware efficiency, the overall trend is much more mild compared to raw compute (especially when considering all models).
Compute Trends Across Three Eras of Machine Learning (Sevilla et al. 2022) [4]
This final paper looks at increases in training compute over the past 70 years of research in machine learning. To do so, they curate a dataset of 123 “milestone” systems and either pull the total compute in terms of FLOPs from their associated papers or estimate it (using two methods which they have previously validated). Specifically, such systems come from papers which must “have received over 1000 citations, be of clear historical importance, demonstrate an important SotA advance, or be deployed in a notable context.” The overall trends they find are given as follows:

They find three distinct eras in machine learning compute: the pre deep learning era, where compute doubled roughly in line with Moore’s law, the deep learning era, where compute doubled roughly every 4-9 months, and a new large-scale era starting in 2015 with the release of AlphaGo, which grows at a slower rate than the deep learning era (doubling every 8-17 months) but with a step jump up in total compute. Notably, the large scale trend is solely being driven by industry organizations which have access to mass resources: OpenAI, Microsoft, Google, and DeepMind.
Discussion
Some thoughts and notes from discussions I’ve had while looking at these papers:
State-of-the art deep models are getting exponentially bigger, which makes it more difficult for people and organizations with limited resources to actually use them (i.e. decreased democratization of AI)
But there are parallel lines of research looking into computational efficiency: there is a push-pull relationship between these lines of research. One group makes a big beefy model, other people apply post-hoc efficiency techniques to make that big beefy model runnable on a reasonable hardware stack. Or, a new and more efficient architecture is developed and then scaled up, so that you ultimately still have a massive model but not as massive or computationally inefficient as a model which would achieve similar results using an older architecture (e.g. vanilla transformer vs. evolved transformer).
There are also improvements in hardware efficiency. Desislavov et al. (2021) [3] show that this has helped keep energy consumption (at least for a single forward pass) from increasing at the same rate as compute.
We can’t forget Jevon’s paradox though – as models become easier to deploy and faster due to increased efficiency, more people will use them.
I would hypothesize that improvements in computational efficiency don’t quite balance out increases in model size and increased use of ML; an actual analysis of the interplay between these three forces at an industry-wide scale would be interesting
I would also note that this would tell us about computation, but you can’t necessarily extrapolate this to energy consumption or carbon emissions (as Desislavov et al. (2021) [3] demonstrate)
There’s also a big difference between training and inference. Training efficiency is important, but many organizations cite it as constituting only 10-30% of the total compute for a given model over its lifetime [5,6]. Additionally, training can be done anywhere that compute resources are available, meaning one can ensure that the carbon emissions for training are held as low as possible by selecting a location where the energy mixture is more green. Inference needs to be done locally to reduce latency. So compute and energy efficiency are more critical for inference when it comes to reducing carbon emissions, because most of the factors one could use to reduce emissions directly are predetermined (i.e. time and location of use).
References
[1] Thompson, Neil C., Kristjan Greenewald, Keeheon Lee, and Gabriel F. Manso. "The computational limits of deep learning." arXiv preprint arXiv:2007.05558v2 (2022).
[2] Hernandez, Danny, and Tom B. Brown. "Measuring the algorithmic efficiency of neural networks." arXiv preprint arXiv:2005.04305 (2020).
[3] Desislavov, Radosvet, Fernando Martínez-Plumed, and José Hernández-Orallo. "Compute and energy consumption trends in deep learning inference." arXiv preprint arXiv:2109.05472 (2021).
[4] Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. "Compute trends across three eras of machine learning." In 2022 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. IEEE, 2022.
[5] Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. "Carbon emissions and large neural network training." arXiv preprint arXiv:2104.10350 (2021).
[6] Wu, Carole-Jean, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang et al. "Sustainable ai: Environmental implications, challenges and opportunities." Proceedings of Machine Learning and Systems 4 (2022): 795-813.
The use of new hardware architectures like the Wafer Scale Engine (WSE) CS-2 system from Cerebras are achieving remarkable improvements in scaling and efficiency over the Nvidia A-1000 GPU. Here's a link to an article that shows how this has impacted big pharma models and oil industry models.
https://www.nextplatform.com/2022/03/02/cerebras-shows-off-scale-up-ai-performance-for-big-pharma-and-big-oil/
Comparisons of the energy efficiency of the CS-2 with the A-1000 is even more amazing. Even with its exponentially better scaling and performance it achieves this with about half the watts per flop.
https://khairy2011.medium.com/tpu-vs-gpu-vs-cerebras-vs-graphcore-a-fair-comparison-between-ml-hardware-3f5a19d89e38