
The Necessary Rabbit Hole of Tracking Carbon Emissions in Machine Learning
What is the environmental impact of ML?

Thanks to Raghav Selvan (@raghavian) for the useful discussions and help researching and editing this essay.
This is a long one so here’s the TL;DR
We don’t exactly know the environmental impact of machine learning in terms of carbon emissions
It is non-trivial to define what emissions to measure and how to measure them — as of now we don’t have any widely adopted standards
I review four recent papers [3,4,5,6] which try to account for and report on the carbon emissions of ML systems, both at an individual level and field-wide level, and derive the following broad observations:
Getting accurate measurements of carbon emissions is difficult
People tend to focus on the training cost, but inference can contribute as much if not more to the total emissions of a model over its lifetime
Based on what you look at, you can derive radically different conclusions about the environmental impact of ML
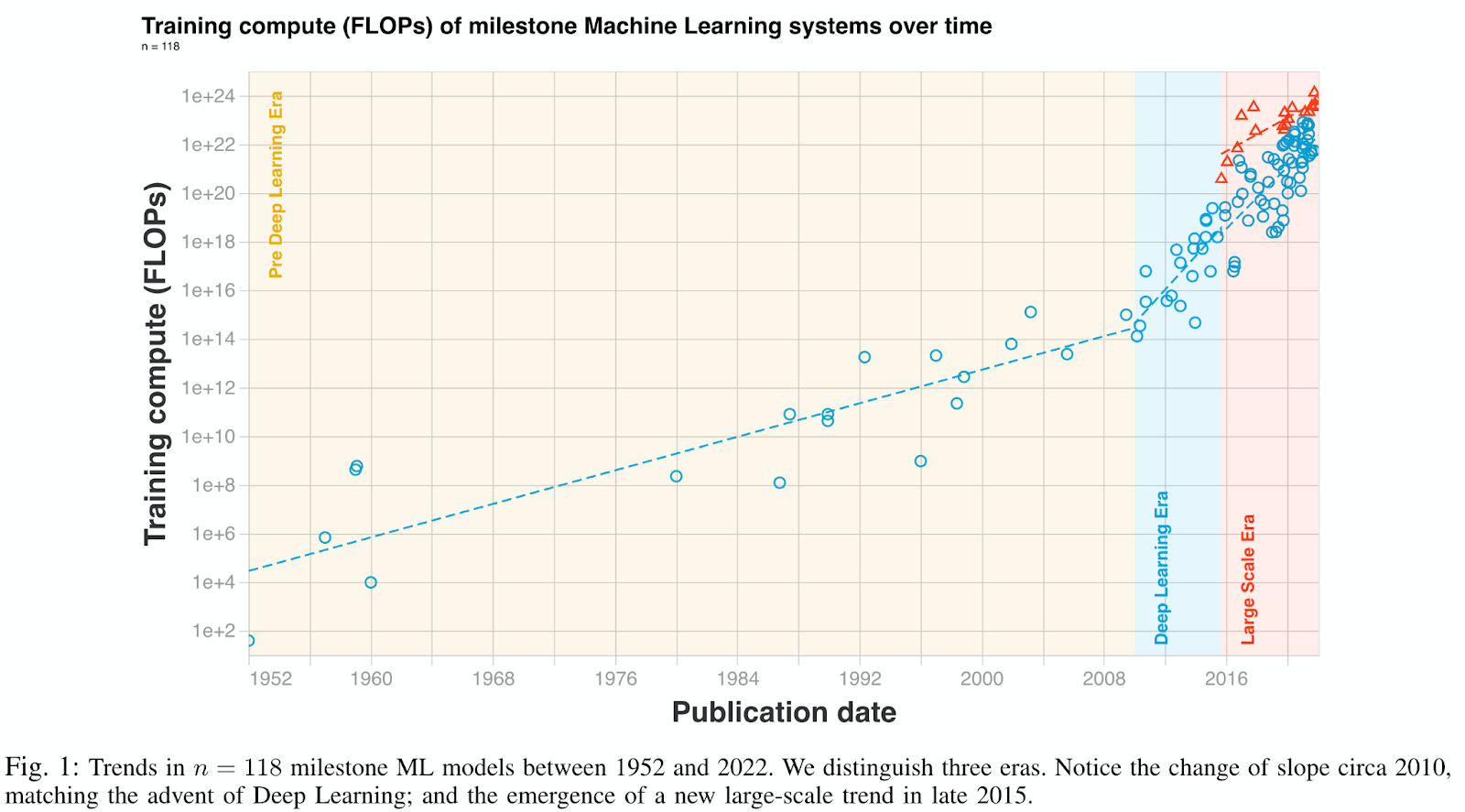
It’s no secret that the computing footprint of machine learning has rapidly increased in the past decade. In fact, we’ve seen two step jumps in recent years in terms of total compute for ML – one around 2010, and one around 2016 [1]. Billion parameter deep models are becoming the norm, at least for anyone with access to massive computational resources and a penchant for large language models. This has happened while the carbon emissions of the information sector as a whole are estimated to be as high as 2.1-3.9% of total greenhouse gas emissions, on par with global aviation. How is ML contributing to these significant emissions?
As of now we don’t exactly know. Accurate reporting and measurement of carbon emissions is necessary for transparency and assessing the environmental impact of ML, understanding the emissions of different parts of the ML development life cycle, and can guide research on how to make ML more sustainable. This can also help spur innovation in related areas such as the compute efficiency of ML. But it is entirely non-trivial to define what emissions to measure and how, and depending on what factors one includes in their measurements and how they measure them, one can come to radically different conclusions about the environmental impact of ML.
Assessing Emissions
The common paradigm used to assess the carbon emissions for a product or service is Life-Cycle Assessment (LCA) [2]:
The basic idea of LCA is that all environmental burdens connected with a product or service have to be assessed, back to the raw materials and down to the waste removal
In the context of product development, this includes the emissions produced by manufacturing, transport, product use, and recycling, and within ML, the main focus is on manufacturing (building and utilizing the data, hardware, and methods for creating models) and product use (building and utilizing the data, hardware, and methods for downstream use of models) [4]. Within those broad categories, we can differentiate two sources of emissions which need to be accounted for:
Operational carbon emissions are the emissions produced by hardware use i.e. from energy consumed when running any computation on actual hardware. Quantifying this involves knowledge of the power consumption of the device(s) the job is being run on (e.g. in Kilowatts (kW); when run in a data center, one should also factor in the power usage effectiveness (PUE) of that data center), the total time that the job is running (e.g. in hours (h)), and the carbon intensity of the power grid (e.g. in equivalent grams of CO2 per kilowatt hour i.e. gCO2eq/kWh). In other words:
Embodied carbon emissions are emissions produced by manufacturing and maintaining the hardware used for computation e.g. producing raw materials, manufacturing, packaging and assembly of hardware, maintaining and cooling the data centers where hardware sits, etc. It is extremely tricky to measure this – you need to have knowledge of the emissions produced from manufacturing your hardware stack. Additionally, to determine the embodied emissions for a particular job, you need to know what percentage of the manufacturing emissions to use, which is dependent on the life-span of the hardware and how long your job will run.
Actually accounting for all of the emissions within these categories is indeed a rabbit hole: within operational emissions, do we only care about the emissions produced by the GPU where our model computations are executed, or do we also care about all of the supporting computation on e.g. CPUs and network cards which run in conjunction with model computations? Within embodied emissions, how do we account for manufacturing costs when the manufacturers don’t release this data, let alone how that cost can or will be amortized across the life-span of that hardware? We don’t have any widely adopted standards for this in our field yet; as a result, there are vastly different estimates, opinions, and projections about the environmental impact of ML.
To highlight this and offer some perspective, I’m going to look at four recent papers which examine and account for emissions in different stages of the ML life cycle. I’ll also illuminate the common and disparate themes, messaging, and measurements used in these papers. I’ll conclude with some thoughts on the main lessons I gained from all four papers about what still needs to be done when it comes to accounting for the carbon emissions of ML.
Luccioni et al. (2022): “Estimating the Carbon Footprint of BLOOM, A 176B Parameter Language Model” [3]
As the title implies, the paper reports on the estimated carbon footprint of BLOOM [7]. BLOOM is essentially the open-source answer to GPT-3, the approximately equivalently sized large language model released by OpenAI (and the original base model for ChatGPT). For some more background on BLOOM:
The BigScience Large Open-science Open-access Multilingual Language Model (BLOOM) is a 176 billion parameter language model. It was trained on 1.6 terabytes of data in 46 natural languages and 13 programming languages as part of the BigScience workshop, a year-long initiative that lasted from May 2021 to May 2022 and brought together over a thousand researchers from around the world.
The paper looks at emissions during the whole life cycle of developing BLOOM, namely on: (1) equipment manufacturing, (2) model training, and (3) model deployment.
Given the difficulty of quantifying embodied emissions (1), they have to rely on estimates: the total emissions of the production of their compute cluster was not available, and the emissions associated with producing the A100 GPUs that they used were not available either.
They also don’t have access to real time power consumption of the GPUs, so they estimate this using the thermal power design (TDP) of the GPUs used, which serves as an upper bound on the energy consumption. Additionally, they don’t have access to the real-time carbon intensity of the grid, so they rely on the average carbon-intensity of the energy grid in France (where the hardware is located) during 2020.
Something related to (2) which is unique is the idle power consumption of the compute cluster where the model was trained. This takes into account the emissions associated with running all of the hardware in the compute cluster not directly involved in running the model (i.e. all hardware that isn’t a GPU or device where model computation is taking place but which is running nonetheless e.g. network components, the CPUs, etc.), giving a more holistic view of the carbon emissions produced by BLOOM.
Finally, for (3), they deploy the model to google cloud platform (GCP) and measure the real time power consumption of the instance over an 18 day period using CodeCarbon [9].
Their main findings can be summarized as follows:
They observe 50.5 tonnes of CO2eq over the development life cycle of BLOOM
This can be broken down into 11.2 tonnes (22.2%) embodied emissions, 24.69 tonnes (48.9%) dynamic power consumption, and 14.6 tonnes (28.9%) idle power consumption (!)
For inference, BLOOM emitted 19kgCO2eq per day when deployed on a GCP instance in the uscentral-1 region (calculated based on the average hourly carbon intensity in that region)
When considering the BigScience workshop as a whole, taking into account the whole experimentation and prototyping of BLOOM, the total emissions add up to 66.29 tonnes of CO2eq operational emissions + 73.32 tonnes embodied and idle emissions
The paper presents an honest view of the emissions produced from developing BLOOM. They rely on estimates where necessary, so it is difficult to say exactly how accurate the figures in the paper are. But the figure about idle consumption is particularly striking to me – it constituted almost 30% of the total emissions from training.
Wu et al. (2022) “Sustainable AI: Environmental Implications, Challenges and Opportunities” [4]
Next, I’ll look at Wu et at. (2022) [4], which takes a holistic perspective of the carbon footprint of ML at Facebook (I’ll focus mostly on their retrospective analysis in Section III). Like Luccioni et al. (2022) [3], they try to account for the whole life cycle of ML development, including data, experimentation, training and inference. Similarly, they also look at both the operational and embodied footprint of each stage of ML development.
They first look at and compare the emissions from 5 Transformer based language models used for text translation at Facebook, as well as some open source models (e.g. Meena, GPT-3, T5). For their in-house models, they are also able to break this down into emissions from offline training (experimentation and training of models on a fixed dataset), online training (updating a model with new training data), and inference, where inference and online training costs are measured over an equal time-period to offline training. They observe equal costs for inference and training for recommendation use cases and greater inference cost for general language modeling e.g. translation. This demonstrates the need to consider the potential cost of inference for a model, while a majority of work that I’ve come across mostly considers the training cost.
One thing to note in the above is that, despite being a centralized entity with their own data centers, they still appear to use only estimates of carbon intensity at their data centers as opposed to real-time intensity, relying on the 2020 Facebook sustainability report. They additionally rely on rough estimates for the embodied emissions, potentially highlighting just how challenging it is to quantify these emissions:
We assume GPU-based AI training systems have similar embodied footprint as the production footprint of Apple’s 28core CPU with dual AMD Radeon GPUs (2000kg CO2). For CPU-only systems, we assume half the embodied emissions. Based on the characterization of model training and inference at Facebook, we assume an average utilization of 30-60% over the 3- to 5-year lifetime for servers.
They then conclude that the split between operational and embodied emissions is 30%/70% for large scale language modeling tasks at Facebook, and that embodied emissions will likely continue to dominate the overall emissions of ML going forward.
Finally, they look at how efficient ML techniques can potentially help reduce the operational energy footprint of large LMs at Facebook. The main conclusion here is that at Facebook, efficient methods have helped to reduce the energy consumed as a percentage of their total energy consumption, but increasing demand has still led to increasing energy consumption from ML systems over time, an example of Jevon’s paradox i.e. increased efficiency lowers the cost of a resource which leads to increased demand, so consumption of that resource increases overall. Finally, they offer several insights and suggestions for reducing both embodied and operational emissions going forward.
Patterson et al. (2022) “The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink” [5]
Another industry paper, this time from Google, Patterson et al. (2022) [5] look specifically at operational emission reductions at Google through two case studies and noting four factors (called 4M) which, if adopted across the industry, would contribute to reductions in carbon emissions. The 4M factors are:
Model: selecting an efficient model architecture can reduce computation and thus energy consumption and potentially emissions.
Machine: specialized hardware such as new GPUs and TPUs can improve performance/Watt by factors of up to 13.7x
Mechanization: computing in cloud data centers can reduce energy costs by a factor of 1.4x
Map: Selecting a better location for computation can reduce the gross carbon footprint due to a better energy mixture
Case study 1 looks at how the 4M factors reduce the “end-to-end CO2e” when using the original Transformer model from 2017 trained in an average (non-google) data center as a reference point. Essentially, (1) looks at improvements in model efficiency (Transformer → Evolved Transformer → Primer), (2) adds improvements in hardware (P100 → TPUv2 → TPUv4), (3) adds better data center efficiency (google data centers have better power usage effectiveness over the average data center), and (4) adds selecting a data center in a location with the lowest carbon intensity.
They report that, by adopting the 4M factors, it is possible to achieve a 747x reduction in end-to-end CO2e. This doesn’t take into account factors related to use e.g. how long it will take to train a model, how long it will be deployed for, how many people will be using it, etc. The improvements in model architectures also don’t take into account the emissions from neural architecture search (NAS) which were required to find them. The basic message is: use more efficient architectures on more efficient hardware in less carbon intensive locations to reduce carbon emissions. Their conclusion is that, given this figure, it is inaccurate to use current day figures to predict the future carbon emissions of ML systems.
Case study 2 compares gross carbon emissions from training two large language models: OpenAI’s GPT-3 and Google’s GLaM [8]. They report a 14x reduction in the emissions from training, which can be attributed to the model being more efficient (though GLaM has more parameters than GPT-3, it uses mixture-of-experts to select which parts of the network to use) and the fact that the model was trained in a more efficient data center with a better energy mixture. Again, this case study is intended to support the position that using current estimates of carbon emissions are likely to overestimate predictions of emissions going forward.
They then perform a retrospective analysis of the percentage of total compute related to machine learning at Google data centers, looking at one specific week in April for 2019, 2020, and 2021. They find that as a percentage of compute, machine learning is holding steady, though overall compute increased over those three years. They argue that improvements in ML efficiency kept ML compute percentage steady despite increased demand (note: another example of Jevon’s paradox at work).
Finally, they argue that previous estimates of the cost associated with particular models (e.g. Evolved Transformer and Primer), were severely overestimated due the the inclusion of NAS in the calculation, and that NAS should have an overall net positive effect due to finding more efficient architectures. In line with this, they echo the work of Wu et al. (2022) [4] to argue that the primary cost is at inference, which constitutes 60% of the ML computation at Google.
Their overall conclusion is that if the 4M factors they list are widely adopted, and innovation in these areas continues, the carbon footprint of ML will plateau and then shrink.
Luccioni and Hernandez-Garcia (2023) “Counting Carbon: A Survey of Factors Influencing the Emissions of Machine Learning” [6]
The final paper I’ll talk about, by Luccioni and Hernandez-Garcia (2023) [6], seeks to quantify and compare the carbon emissions produced during training by ~100 state of the art models from the past decade. The paper is thorough – in addition to gleaning necessary details from the papers for each of the models, they contact and retrieve additional information from the authors, including:
Where the models were trained
The hardware used
The total training time of the models
Given this, they are able to characterize and compare:
The main sources of energy (based on location) used to train those models
Estimations of the carbon emissions produced by each model
The evolution of carbon emissions over time in the field
The relationship between performance and carbon emissions
While they rely on estimation by necessity, and it is hard to say how accurate such estimations are, the paper gives a view into what sorts of insights can be gained by performing standardized comparisons of the carbon emissions of a wide set of models across time. The caveat being that they too don’t look holistically (though they look more widely than any other paper I’ve seen): they look only at model training, and only a subset of models in the field (albeit very important ones).
They also provide evidence which contradicts Patterson et al. (2022) [5]: based on their analysis, the carbon footprint of ML is actually increasing over time.
If we look at the aggregated data from all tasks… we can observe that overall, the carbon emissions per model have increased by a factor of about 100 (two orders of magnitude) from 2012 to recent years, with slight fluctuations, as in 2020… In fact, the last three years of our sample (2019-2021), have seen models that have emitted orders of magnitude more carbon than before
Note the similarity with the results from [1], included at the beginning of this essay: a step jump in model size around 2016 and a step jump in carbon emissions around 2019.
Lessons Learned and Conclusions
Getting accurate measurements of emissions is difficult
In all of these papers, they rely on estimates for the operational footprint (using regional average carbon intensities, using the TDP of the GPUs as a proxy for real-time energy consumption, etc.) and embodied footprint (which requires making lots of assumptions about your hardware; Patterson et al. (2022) [5] doesn’t take this into account at all). Something useful here would be to at least give some expectation over the possible range the measurements could take e.g. a lower and upper bound. And in the case of operational emissions, using real-time measurements of carbon-intensity would give a much more accurate view of the actual carbon emissions.
People tend to focus on the training cost, but inference can contribute as much if not more to the total emissions of a model over its lifetime
Wu et al. (2022) [4] and Patterson et al. (2022) [5] demonstrate this quite clearly by comparing offline training vs. online training and inference over equal time periods.
Based on what you look at, you can derive radically different conclusions about the environmental impact of ML
Luccioni et al. (2022) [3] make this abundantly clear when taking into consideration idle compute costs, which accounted for more that 28% of emissions when training BLOOM. Had Wu et al. (2022) [4] considered this, perhaps their conclusion about embodied emissions becoming the dominant cost in ML going forward would change. Patterson et al (2022) [5] opt to look at potential reductions from specific interventions rather than looking holistically. This results in contradicting conclusions between their work and Luccioni and Hernandez-Garcia (2023) [6] about trends in carbon emissions in the field as a whole if we project out into the future.
In this, the estimates that different people provide about the environmental impact of ML are potentially more reflective of their own pessimism or optimism about the field. Conflicts of interest are also a factor here. Standards for reporting can help mitigate this.
It’s also hard to fairly compare the emissions associated with specific models: you’ll get different results depending on which estimates of energy consumption and carbon intensity you are using, which computations you choose to include in the energy consumption, and which assumptions you make about the hardware stack you are using. This further obviates the need to explicitly define which carbon emissions should be included and how to estimate/measure them when characterizing the environmental impact of ML systems.
Developing this definition and best practices is a goal worth striving for: by doing this, we can begin to make fair and accurate comparisons of the emissions produced by different models at different stages of their life-cycle, and quantify the environmental impact of the field as a whole. Yes it is difficult and yes it is a rabbit hole: but it is one that is necessary to traverse in order to better align with the values of sustainability in machine learning. And it might just illuminate new research directions to explore in the context of sustainable ML.
References
[1] Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. "Compute trends across three eras of machine learning." In 2022 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. IEEE, 2022.
[2] Klöpffer, Walter. "Life cycle assessment: From the beginning to the current state." Environmental Science and Pollution Research 4 (1997): 223-228.
[3] Luccioni, Alexandra Sasha, Sylvain Viguier, and Anne-Laure Ligozat. "Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model." arXiv preprint arXiv:2211.02001 (2022).
[4] Wu, Carole-Jean, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang et al. "Sustainable ai: Environmental implications, challenges and opportunities." Proceedings of Machine Learning and Systems 4 (2022): 795-813.
[5] Patterson, David, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R. So, Maud Texier, and Jeff Dean. "The carbon footprint of machine learning training will plateau, then shrink." Computer 55, no. 7 (2022): 18-28.
[6] Luccioni, Alexandra Sasha, and Alex Hernandez-Garcia. "Counting Carbon: A Survey of Factors Influencing the Emissions of Machine Learning." arXiv preprint arXiv:2302.08476 (2023).
[7] Luccioni, Alexandra Sasha, Sylvain Viguier, and Anne-Laure Ligozat. "Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model." arXiv preprint arXiv:2211.02001 (2022).
[8] Du, Nan, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun et al. "Glam: Efficient scaling of language models with mixture-of-experts." In International Conference on Machine Learning, pp. 5547-5569. PMLR, 2022.
[9] Lacoste, Alexandre, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. "Quantifying the carbon emissions of machine learning." arXiv preprint arXiv:1910.09700 (2019).
Thanks for the very informative survey! I agree with you that Jevon’s paradox is a serious concern - we can develop more efficient ML, but if it means we just apply it indiscriminately then we're worse off in the end. We should think more holistically not just in terms of lifecycle, but also impact - are the externalities of ML worth the gain to society (or the environment if we're talking about ML for positive environmental impact) or is it just for fun/money? This is one of the points we made in our EMNLP paper last year (https://aclanthology.org/2022.emnlp-main.159/). Another point was that as you say, standardized reporting is important, but arguably widespread reporting is even more important, so that we don't need to personally contact dozens of authors like Luccioni and Hernandez-Garcia did to conduct a meta analysis. If you overemphasize accuracy then people will just avoid the headache of reporting unless they really have to. But if it's easy to report some details then they might as well so it (this is also related to the topic of behavior change, which you wrote about in the previous post). That's why we proposed a relatively lightweight model card for this purpose.
Another very recent paper, which was just accepted to NoDaLiDa 2023, proposes an abstract metric to quantity the tradeoff between model development and deployment (https://openreview.net/forum?id=-O-A_6M_oi). I think they make a good point: some times we don't need perfectly accurate measures, but we need to quantify the relative impact of the available alternatives in order to make an informed decision. For this purpose, too, it's better to have estimates for all alternatives even if they're not perfect.
What strikes me about the question of the CO2 emissions produced by training a machine model as a proportion of its energy input is that it exactly parallels the thermodynamic relationships encountered by all living systems. Karl Friston is a neuroscientist who developed the "Free Energy" theory for biological systems. Free energy is the amount of energy available to do work after subtracting the energy lost in all forms of entropy and heat from total energy. The CO2 produced when hydrocarbons burn is part of the energy lost to entropy.
In a simplified form, biological learning systems continuously compare their internal state model with a predicted state of the environment model and use sensory feedback signals to correct the internal state error distance. The "goal" of living things is to maximize the free energy available to do this. "Goal" implies some agency or intentionality but its really just natural selection at work. Those that are more fit to do this keep evolving, those that are less fit and incur a higher cost go extinct.
An interesting experiment would be to design a machine learning platform that incorporated feedback on its energy consumption and carbon footprint and applied an evolutionary model optimization algorithm to maximize the free energy available to accomplish its model training and inference functions.
If you gave such a system a novel task that required more energy to train, would it first demand more energy before it tried? Would it try to steal energy from other models in the lab? Would some of the models evolve different architectures that combined processing or outsourced functions from other models that reduced its energy consumption? If it got greedy and started crashing energy competitors, could we ethically shut it down? Once machines develop the same energy imperatives as living systems, can we say they are alive?